Leaderboard
-
Hazza12555
Members5Points74Posts -
id-daemon
Engineers4Points346Posts -
shak-otay
Engineers4Points1,455Posts -
Scobalula
Members3Points11Posts




Popular Content
Showing content with the highest reputation since 06/27/2026 in all areas
-
2 pointsNew Version of TASM 1+2 Tools Audio is now sorted/named Also sorted into languages.2 points
-
2 pointsWas heavily tied up in other stuff - including building up my utility library for other projects (that would include this), I'm hoping to have an OSS release at some point this week, the tool has undergone major refactoring under the hood and I've figured out where the game handles those invalid version meshes, along with texture bindings, etc. With the upgrades to my utility library the tool will support more formats such as SMD, FBX, etc.
 2 points
2 points -
1 pointYeah, textures seem to be converting and looking 100% fine now. Thanks a lot for that, bruv.1 point
-
1 pointok new version posted. You need to re-dump (only chunks) to get HD chunks now.1 point
-
@Lugg: I've reported your ungrateful PM which showed me that guys like you don't deserve any help. You're on my ignore list now, btw.1 point
-
1 point
-
1 point
-
The dirty way.... Thing is each resource is aligned to 16 bytes and i don't know how to do it in bms. I tried padding but it fails. get FileSize asize get BaseFileName basename get FileExtension extension for FindLoc ResOffset string "\x44\x3A\x5C\x70\x72\x6F\x67\x72\x61\x6D\x6D\x65\x72\x5F\x50\x43" goto ResOffset savepos StrOffset get FilePath string goto StrOffset getdstring Dummy 0x100 get ResourceSize uint32 savepos ResourceOffset getdstring ResourceData ResourceSize string Name p "%s/%s/%s" BaseFileName FileExtension FilePath #print "%Name%" log Name ResourceOffset ResourceSize nextAlso i can see some files uses zlib/deflate compression.1 point
-
Well, it's too poor to be released. But I pmed you what I had so far, Dec. 24, recompiled.1 point
-
1 pointWhere have you found SX 6.0? I can't find any reference to it anywhere on the internet. I believe the latest I've found is v4 EDIT: Nevermind I just saw another post of yours that has the link. Thank you!1 point
-
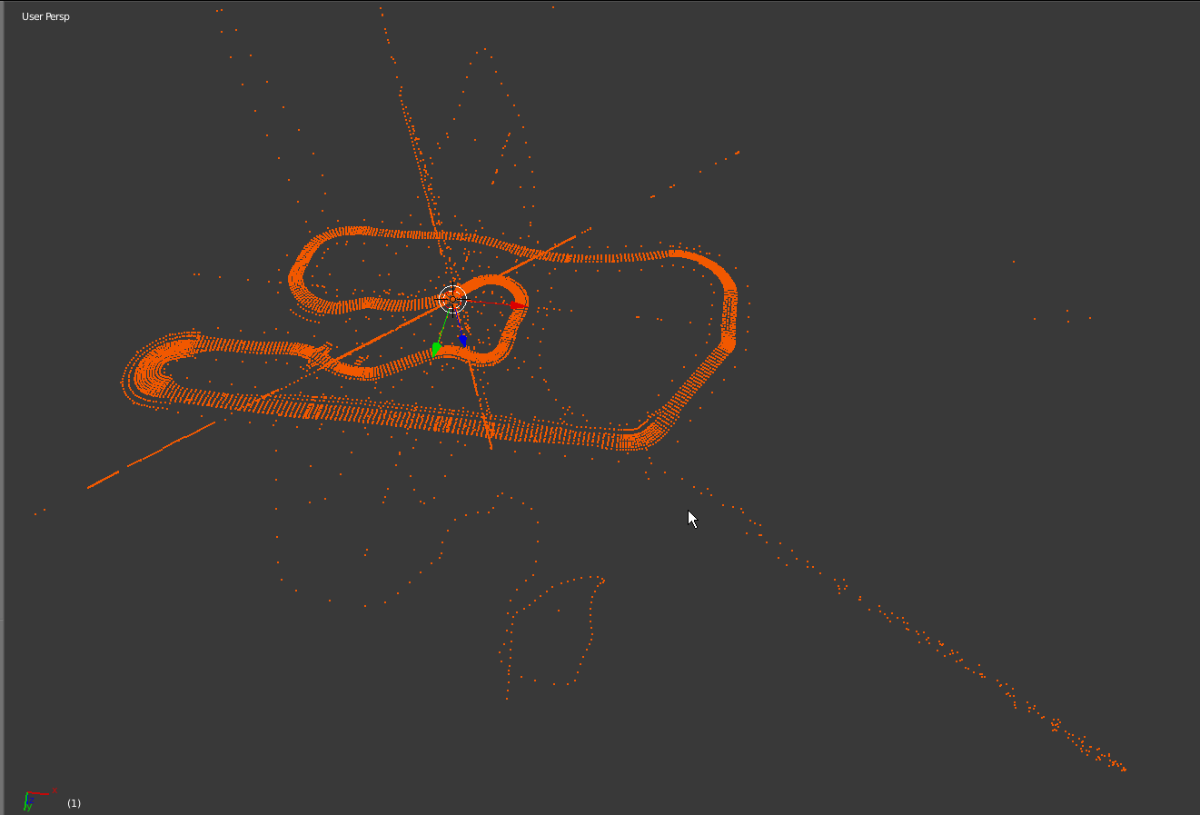
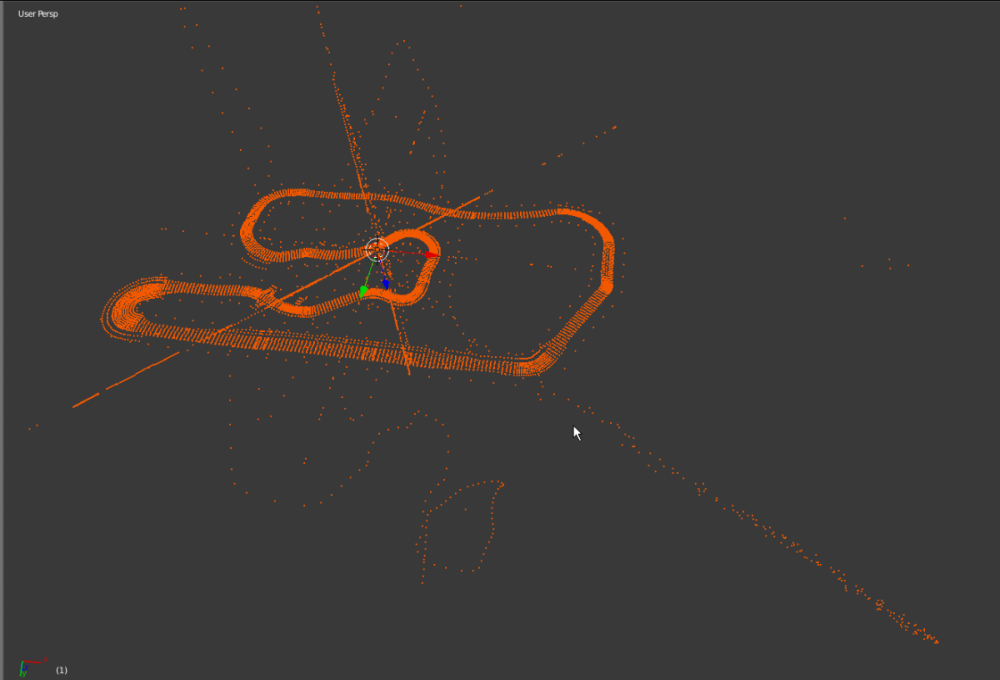
After having searched through many too many senseless (?) blocks I finally got this (deepforest):
 1 point
1 point -
The game just uses encryption, not LZRW. I made a mistake with another tool and file that I was examining together with this one... lol. But the tool I made works just fine with the file, so it doesn't need an update.
 1 point
1 point -
1 point100% I'm planning on doing it for all of the games, they all use the same engine with slightly different modifications.1 point
-
1 pointI'm looking for tools to extract or create add-on/mod archive files for Max Payne. RAS file has header and filename encryption. Here is the file format specification: http://fileformats.archiveteam.org/wiki/Remedy_Archive_System Here is RASMaker which is included in the official Max Payne mod development toolset. maxpayne_ras.zip maxpayne_rasmaker.rar1 point
-
1 pointadded extraction support, should work on files with versions beside 1.2 but untested same with compressed files: https://github.com/smiRaphi/UniPyX/commit/10b71fe85dbc064334ff472caadb6525fb1b5b851 point
-
We are currently testing whether we can retrieve character IDs from the database and read all related data1 point
-
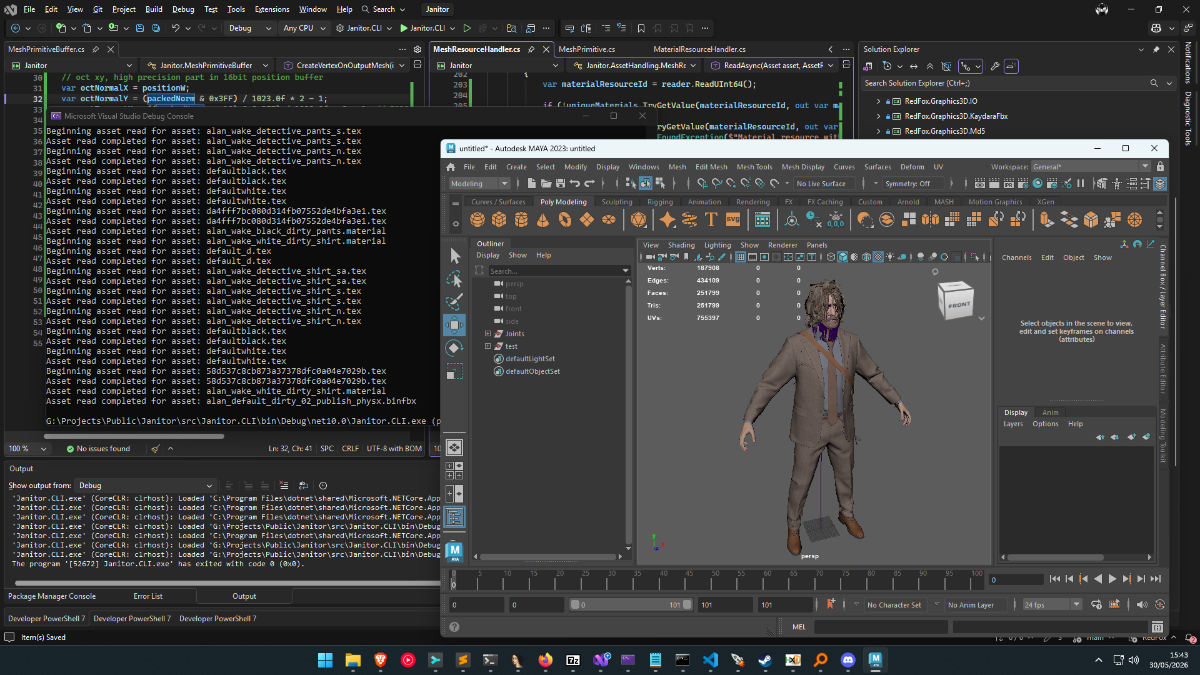
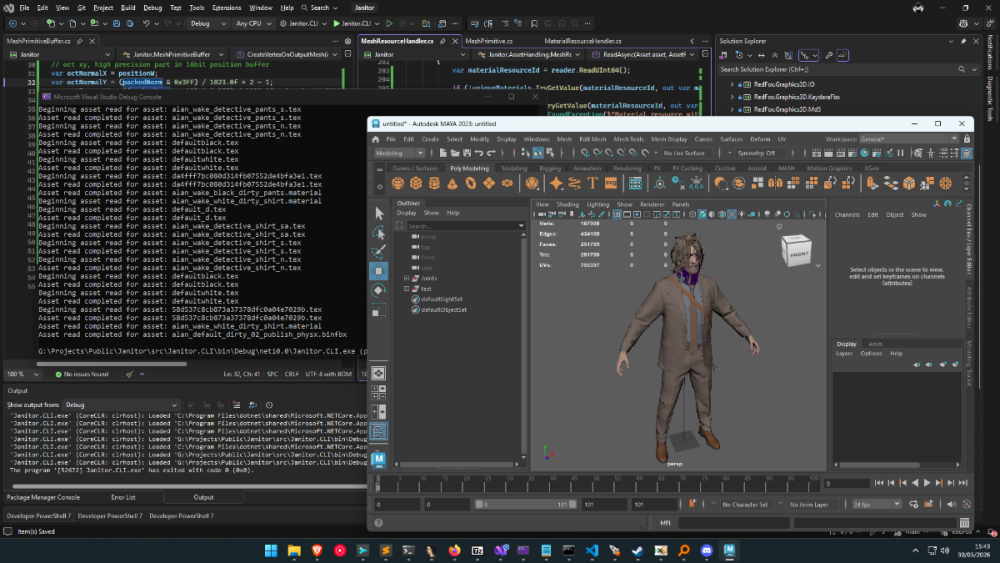
 Extremely early version of tool, can export a good portion of models in game, some will fail due to version (investigating if this is due to them being old files, or if the game genuinely has a different code path for them, as I can only see 1 in the exe). Some will also fail due to WIP issues with mapping LOD indices (errors or corrupt mesh output) Drag and drop Alan Wake 2's folder onto the exe/pass it via CLI and it will export all binfbx files in the archives. Currently only exports models with material names/skeleton, references to textures and other data is a heavy work in progress, but I felt it was best to get an early version out that can at least export mesh info. Requires Cast plugin to import into Blender/Maya for now, more formats will be supported later: https://github.com/dtzxporter/cast Janitor.CLI.7z1 point
Extremely early version of tool, can export a good portion of models in game, some will fail due to version (investigating if this is due to them being old files, or if the game genuinely has a different code path for them, as I can only see 1 in the exe). Some will also fail due to WIP issues with mapping LOD indices (errors or corrupt mesh output) Drag and drop Alan Wake 2's folder onto the exe/pass it via CLI and it will export all binfbx files in the archives. Currently only exports models with material names/skeleton, references to textures and other data is a heavy work in progress, but I felt it was best to get an early version out that can at least export mesh info. Requires Cast plugin to import into Blender/Maya for now, more formats will be supported later: https://github.com/dtzxporter/cast Janitor.CLI.7z1 point -
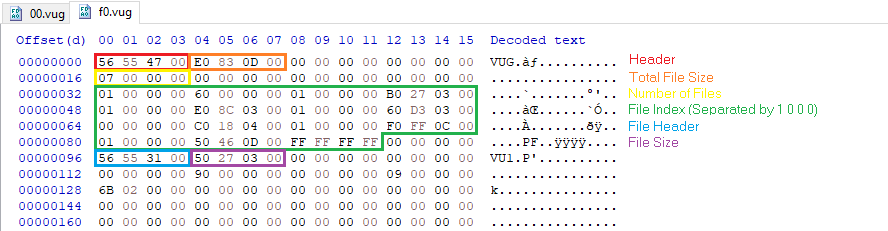
So here are my findings that could be useful to anyone who wants to improve the current Noesis script. It's not 100% accurate, but it's a good majority of what's documented. The VUG files first starts out with the header and total file size, then the number of VU1 or VU0 models that are inside, and then the index of offsets where the said files are located. The header of the VU1 and VU0 files are mostly the same with the first 4 bytes and then the file size of it. And then you have the file headers inside the VU1 files. The file header is always "04 04 00 01". After that comes 4 bytes which are the version of VU1, either "00 80 02 6C" (52 bytes) or "00 80 01 6C" (36 bytes) and they both behave differently from each other. There are some versions where the bytes are "## 00 04 6C" or "##" 00 01 6C", but I don't know what they're for. (Maybe bones? Who knows.) After those 4 bytes comes an early vertex/uvs/normal count for the mesh that it searches for. And after that there's the file ID in bytes "00 40 2E 30" for the regular meshes that the current script can grab, or "00 C0 2D 30" for the rest of the geometry that the script misses (The holes!). After that comes 4 bytes of "12 04 00 00" which is mostly consistent, and then there's 4 bytes after that are different from the two versions. "00 00 00 00" for the "02 6C" files, and "0C 00 00 00" for the "01 6C" files. If the ID is "00 C0 2D 30" then it's a "0B" instead. After that there's one more set of 4 bytes that are different from the versions too, "05 01 00 01" and "04 01 00 01". And then comes the actual mesh data. Listed in the picture down below is a comparison between the two versions of how the vertices, uvs, normals and faces are handled as they have one slight byte difference. VU0 models have still yet to be documented as there are some VU0 models inside some of the VUGs that are of a character's face, miscellaneous objects, etc, and are handled completely different compared to the VU1 models. But anyhow, I hope this helps out a bit for improving the mesh script. Best regards!
 1 point
1 point -
This project looks kinda abandoned, to be honest. Since you wrote you don't know jack about hex or anything like that I wasn't sure to upload an unfinished Make_obj exe in fear of the confusions it could cause. Anyways here's the latest obj file from Gantz I could find which is obviously the one from here: testGantzFakeTriStrips.zip1 point