Search the Community
Showing results for tags 'pc'.
Found 14 results
-
I'm trying to figure out how to extract the .dat files in QP Shooting to translate it to English. (Not putting it in the Game Localization category as I do not need help with translation itself) QP Shooting is a bullet hell game released in 2004. It uses the Luna3D engine (pretty obscure Japanese game engine using DirectX, near impossible to find) About the Game Engine: From the game's main .exe file: Luna3rd Phase 10.20... 2003.07.29 Luna Homepage | twin-tail.jp/contents/luna/index.htm There's a game called Magical Broom Extreme made by the author of the engine. Might be helpful. The source code isn't included in "All Package", so you'll have to download that one separately from the rest. Self Extracting Installer | twin-tail.jp/contents/game/mbx/index.htm About the Game: QP Shooting Download (Trial, should be sufficient): daidai.moo.jp/dl.html Download is at the bottom of the list, 13MB. Right click and open as new tab for the Dropbox link to work. Presumably compiled with Borland C++. Checking the .exe in a hex editor shows some things: file names from the inside of the .dat files dat\st_00.txt through st_06.txt as previously listed, it uses Luna3rd Phase 10.20... 2003.07.29 along with that, it uses DirectX 8.1 And for the .dat files: some have a LAG/4C 41 47 file header (stg3.dat, stg4.dat, stg5.dat, stg6.dat) BMP converted to LAG (Luna image format) some have legible text, likely for filenames stg3.dat: "bgp_01", etc. (looks like main menu + UI stuff) stg4.dat: "face_mi01", "face_qp01", "face_qp02", "face_yu01", "face_yu02" (face sprites) the 2 letters before the last 2 numbers are in reference to which character's portrait it is stg5.dat: "cutin_01", "cutin_06" stg6.dat: (presumably) stuff relating to winning and bullet formations The later games made by the same developer use DXArchive from DXLibrary, but it's different for the older games. I figure I should link it just in case. (Source) / Link to DXLibrary
-
 I've been interested in trying to rip the files for the Open Season videogame to unearth any unused files present for a couple of years, found some filenames for unused stuff like a wolf character among other things in the .UMD package file which the game requires in the Xbox 360, Xbox, and PC versions to even bootup (while also using .lin and liv files for packages (.liv being exclusive to the Xbox 360 version), PS2, GameCube and Wii have the contents of the .lin and .liv files included in the main .UMD package file that's required to boot the game up. Though there's been no way to view this stuff for 18 and a half years since the release of the movie and the tie-in game here. Here's files as samples from every version of the main Console/PC releases for research purposes from anyone willing to look into this, which would be really awesome. Versions included: Xbox 360 (North American Version) Xbox (North American Version) PC (North American Version) PS2 (1st European version (English, French, Spanish, Dutch) since it's the earliest final retail build of this release compared to the Scandinavian European PS2 version) GameCube (North American Version) Wii (North American Version) https://drive.google.com/drive/folders/1lTmfQnIQhtK099_aeYbiDBTHjNbwY7oh?usp=sharing
I've been interested in trying to rip the files for the Open Season videogame to unearth any unused files present for a couple of years, found some filenames for unused stuff like a wolf character among other things in the .UMD package file which the game requires in the Xbox 360, Xbox, and PC versions to even bootup (while also using .lin and liv files for packages (.liv being exclusive to the Xbox 360 version), PS2, GameCube and Wii have the contents of the .lin and .liv files included in the main .UMD package file that's required to boot the game up. Though there's been no way to view this stuff for 18 and a half years since the release of the movie and the tie-in game here. Here's files as samples from every version of the main Console/PC releases for research purposes from anyone willing to look into this, which would be really awesome. Versions included: Xbox 360 (North American Version) Xbox (North American Version) PC (North American Version) PS2 (1st European version (English, French, Spanish, Dutch) since it's the earliest final retail build of this release compared to the Scandinavian European PS2 version) GameCube (North American Version) Wii (North American Version) https://drive.google.com/drive/folders/1lTmfQnIQhtK099_aeYbiDBTHjNbwY7oh?usp=sharing -
(Little preamble:) Unsure if I should post each archive format separately... I'll start with this one, as I have it best described atm. I reversed bunch of other audio-related formats of Glacier 1 games so I plan to slowly put them all here. Take this as an appetizer 😛 Streams files of Glacier 1 games can be read on their own, they contains all of the required data. It should actually be read before any scenes when someone wants to do anything audio-related to have best support, unlike older Glacier 1 games which had streams.wav. Data in file can be separated into following sections, some have clear indices some can be implicitly inferred: - header - block of WAV data (also contains LIP-encoded segments in some data, current exact structure of these is unknown...) - block of WAV headers (different format than headers in *.WHD files, is much simpler and more concise) - file name table (file names match those in *.WHD and *.SND files, there are some extras though contained within this file so this is not full subset!) - records table (start marked in header along with records count) Block of WAV data seems to be aligned on 0x100 boundary (which coincidentally seems to also be size of header and offset to block of WAV data...). Rest of the file does not seem to have any specific alignment. Any WAV data may be encoded in LIP segments which have variable length. Header of the LIP chunks seems to have size of 0xF00 or 0x1000 (with first header containing 'LIP ' magic). Each record seems to contain a field which can be checked to see if data contains LIP segments or not without the need to rely on comparing magic of each data block. For distance-based records, you will have to look into master record to see if LIP encoding is used. There may be multiple LIP segments in the data block, but only first one has magic in first four bytes. Due to variable data length, we have to find out the right size of the LIP segment first before parsing. It seems to appear roughly every ~4 seconds, but naive formula of `average byte rate * 4` just roughly yields what the LIP segment is. Therefore, there is some guessing work that has to be done on the algorithm side to extract data properly. If anyone could help with reversing these LIP segments, it would be great! They do not seem to correspond to speech necessarily. Current detection method for LIP segments relies on the fact that archive is aligned, we know roughly where the offset should be and that we can calculate exact size of each data block (next block offset - current block offset). There is also additional observation to be made that nearly all LIP segments seem to have around half of their data filled with zeroes. We can also notice that when we subtract real data size, aligned on 0x100 boundary, from whole data block size, we get amount of bytes belonging to LIP segments. We can then calculate from this size amount of LIP segments in the data block. There may be only one such segment (calculated size of all LIP segments is <= 0x1000), which does not require us to do any magic - we just have to skip past the header and read real data right after it. Note that the size of the block may be 0xF00 and not 0x1000 so <= and skipping whatever offset you get is probably best course of action until the segments are bit better understood. If there are more segments, we can proceed with calculation of segment size (as the data is interleaved in a way described above). As mentioned before, we roughly know when each of LIP segments appears in the audio file (it is roughly equivalent to 4 seconds, leaving last block unaligned most of the time with smaller size). We should try to pattern match buffer of size 0x780 filled with zeroes, masking each found offset with ~0xFFF (which will left-align on 0x1000) and taking closest offset to the one we predicted. We then read in minimum from "data block bytes left to read" and this "found LIP segment offset", skip 0x1000 bytes to get "divider offset" for the encoded block and copy each part of the segment into its own buffer. In the end, we are left with complete LIP data and complete WAV data. Block of WAV data is organized in such a way that it has all non-distance-based entries at the beginning and all distance-based entries at the end. There is no clear block of LIP data, it seems to be mixed randomly in-between all of the entries so no reliable distinction in the block. Distance-based entries point to same data offset, there are always exactly three such pointers (2 defined in *.WHD which have their copy in *.STR file also, 1 is only defined in *.STR file). There cannot be other number of "duplicates" pointing to same data offset than 1 (none) or 3 (distance-based entry, 1 for master and 2 for near/far data). Third entry we mentioned is STR file only, it is the true data definition used by the sound graph. If LIP data is present, master record has appropriate flag set. Note that master record should not really be used for other things, as its parameters are not exactly the same always and correct ones are located directly in the entry. TODO - add information about distance-based records structure, it is also interleaved... Due to all this, recommended way to get to the actual data is to pre-calculate all individual WAV data block sizes and resolve LIP segment sizes for each record along with detecting which records are distance-based. TODO - add parsing process used by Glacier 1 Audio Tool which seems to have correct export Note that format information of data, along with data sizes, offsets, names, etc. are all the same as one can find in their equivalent records in *.WHD files. So there is no need to reference *.WHD files for any sort of information for extraction of the *.STR files (unlike older Glacier 1 games). Below are simple C++ headers which should help anyone interested to get started with the file format I hope! V1 is for Hitman: Blood Money V2 is for Kane & Lynch: Dead Men and Mini Ninjas V3 is for Kane & Lynch 2: Dog Days (TODO - missing information+header!) // // Created by Andrej Redeky. // SPDX-License-Identifier: Unlicense // // Extended format information: https://reshax.com/topic/27-glacier-1-str-file-format // #pragma once enum class STR_LanguageID_v1 : uint32_t { Default = 0, English = 1, German = 2, French = 3, Spanish = 4, Italian = 5, Dutch = 6 }; struct STR_Header_v1 { char id[0xC] = {'I', 'O', 'I', 'S', 'N', 'D', 'S', 'T', 'R', 'E', 'A', 'M'}; // always "IOISNDSTREAM" uint8_t unkC[0x4]; // always seems to be a sequence 09 00 00 00 uint32_t offsetToEntryTable = 0; // points at the STR_Footer, right after string table ends uint32_t entriesCount = 0; // same as number of STR_Data entries in STR_Footer uint32_t dataBeginOffset = 0x100; // offset to beginning of data probably, but it is like this even for PC_Eng.str which does not have such size and has no data... uint8_t unk1C[0x8]; // always seems to be a sequence 00 00 00 00 01 00 00 00 STR_LanguageID_v1 languageId = STR_LanguageID_v1::Default; // specifies which language data is contained within the archive }; enum class STR_DataFormat_v1 : uint32_t { INVALID = 0x00, PCM_S16 = 0x02, IMA_ADPCM = 0x03, OGG_VORBIS = 0x04, DISTANCE_BASED_MASTER = 0x11 }; // beware that this is really 3 different headers, as there is no padding... didn't know how to name things so left it like this for now.. struct STR_DataHeader_v1 { // PCM_S16, IMA_ADPCM, OGG_VORBIS and DISTANCE_BASED_MASTER have following bytes STR_DataFormat_v1 format; // specifies how data should be read uint32_t samplesCount; // samples count uint32_t channels; // number of channels uint32_t sampleRate; // sample rate uint32_t bitsPerSample; // bits per sample // all PCM_S16, IMA_ADPCM and DISTANCE_BASED_MASTER have following bytes on top uint32_t blockAlign; // block alignment // all IMA_ADPCM have following bytes on top uint32_t samplesPerBlock; // samples per block }; struct STR_Entry_v1 { uint64_t id; // probably some ID, is less than total entries count, does not match its index uint64_t dataOffset; // offset to beginning of data, beware of the distance-based records which alias the same index! uint64_t dataSize; // data size uint64_t dataHeaderOffset; // offset to table containing header uint32_t dataHeaderSize; // size of STR_DataHeader_v1 (unused fields from the structure are left out) uint32_t unk24; // unknown number uint64_t fileNameLength; // length of filename in string table uint64_t fileNameOffset; // offset to filename in string table uint32_t hasLIP; // 0x04 when LIP data is present for current entry, 0x00 otherwise uint32_t unk3C; // unknown number uint64_t distanceBasedRecordOrder; // if 0, entry is not distance-based, otherwise denotes data order of individual records in data block (or is simply non-zero for master record) }; enum class STR_LanguageID_v2 : uint32_t { Default = 0, English = 1, German = 2, French = 3, Spanish = 4, Italian = 5, Dutch = 6 }; struct STR_Header_v2 { char id[0xC] = {'I', 'O', 'I', 'S', 'N', 'D', 'S', 'T', 'R', 'E', 'A', 'M'}; // always "IOISNDSTREAM" uint8_t unkC[0xC]; // always seems to be a sequence 09 00 00 00 XX XX YY YY 00 00 00 00 where XX XX changes with language and game and YY YY is same for a game (Kane & Lynch: Dead Man has this sequence E1 46, Mini Ninjas has this sequence 4C 4A) uint32_t offsetToEntryTable = 0; // points at the STR_Footer, right after string table ends uint32_t entriesCount = 0; // same as number of STR_Data entries in STR_Footer uint32_t dataBeginOffset = 0x100; // offset to beginning of data probably, but it is like this even for PC_Eng.str which does not have such size and has no data... uint8_t unk24[0x8]; // always seems to be a sequence 00 00 00 00 01 00 00 00 STR_LanguageID_v2 languageId = STR_LanguageID_v2::Default; // specifies which language data is contained within the archive uint8_t unk30[0x8]; // always some sequence 38 XX XX XX XX XX XX XX where XX is same for a game (Kane & Lynch: Dead Man has this sequence 00 A1 01 18 EE 90 7C, Mini Ninjas has this sequence 00 00 00 00 00 00 00) }; enum class STR_DataFormat_v2 : uint32_t { INVALID = 0x00, PCM_S16 = 0x02, IMA_ADPCM = 0x03, OGG_VORBIS = 0x04, UNKNOWN_MASTER = 0x1A }; // beware that this is really 2 different headers, as there is no padding... didn't know how to name things so left it like this for now.. struct STR_DataHeader_v2 { // PCM_S16, IMA_ADPCM, OGG_VORBIS and UNKNOWN_MASTER have following bytes STR_DataFormat_v2 format; // specifies how data should be read uint32_t samplesCount; // samples count uint32_t channels; // number of channels uint32_t sampleRate; // sample rate uint32_t bitsPerSample; // bits per sample uint32_t unk14 = 0; uint32_t unk18 = 0; uint32_t blockAlign; // block alignment // all IMA_ADPCM have following bytes on top uint32_t samplesPerBlock; // samples per block }; struct STR_Entry_v2 { uint64_t id; // probably some ID, is less than total entries count, does not match its index uint64_t dataOffset; // offset to beginning of data, beware of the distance-based records which alias the same index! uint64_t dataSize; // data size uint64_t dataHeaderOffset; // offset to table containing header uint32_t dataHeaderSize; // size of STR_DataHeader_v2 (unused fields from the structure are left out) uint32_t unk24; // unknown number uint64_t fileNameLength; // length of filename in string table uint64_t fileNameOffset; // offset to filename in string table uint32_t hasLIP; // 0x04 when LIP data is present for current entry, 0x00 otherwise uint32_t unk3C; // unknown number uint64_t unk40; // OLD INFO: if 0, entry is not distance-based, otherwise denotes data order of individual records in data block (or is simply non-zero for master record) };
-
Seems like Nihon Falcom made their own file format similar to .p3a archive format from YS X (international version). .pac file Sample.zip

-
 Psi-Ops is a short experience with an irrelevant story that I think would be sweet to make quick character mods for, especially since the game comes with unlockable outfits and characters for campaign use with mechanical changes compared to the base character. However, from what I understand it was built using a modified UE2 engine and no one really knows a whole lot about the formats. The game was actually released for free on PC, and after its parent company also ceased to be. Thus it should be accessible without any potential legal issue here https://www.myabandonware.com/game/psi-ops-the-mindgate-conspiracy-dvc Watto's Game Extractor can seemingly extract data from the .w32 archives (which appear to contain the desired character data), and I asked Watto himself to take a look at "MAINNICK.w32" in the included attachment and he had this to say, Thus, I am now here! Inside of the "MAINNICK.w32" appears to be: .smsh (skinned mesh) .skel (skeleton) .tbx (texture) //guessing it's only a diffuse texture, game probably doesn't have more than that lol .tex (material) .strs (???) .vbx (???) //referred to as a "global vertex buffer" I also included MAINPK, as she's one of the unlockable skins, just incase there's potential variation as the aformentioned character is the base skin, which allows cutscenes and hitgrunts. In addition, i've also included what appears to be the games general containers (divided by language given the final character) which includes .mesh files, which I'm assuming is static mesh. Let me know if anyone is willing to make .bms and/or noesis import/export scripts (anything that would allow me to make character replacer mods) I'd be super grateful! Psi-Ops W32s.zip
Psi-Ops is a short experience with an irrelevant story that I think would be sweet to make quick character mods for, especially since the game comes with unlockable outfits and characters for campaign use with mechanical changes compared to the base character. However, from what I understand it was built using a modified UE2 engine and no one really knows a whole lot about the formats. The game was actually released for free on PC, and after its parent company also ceased to be. Thus it should be accessible without any potential legal issue here https://www.myabandonware.com/game/psi-ops-the-mindgate-conspiracy-dvc Watto's Game Extractor can seemingly extract data from the .w32 archives (which appear to contain the desired character data), and I asked Watto himself to take a look at "MAINNICK.w32" in the included attachment and he had this to say, Thus, I am now here! Inside of the "MAINNICK.w32" appears to be: .smsh (skinned mesh) .skel (skeleton) .tbx (texture) //guessing it's only a diffuse texture, game probably doesn't have more than that lol .tex (material) .strs (???) .vbx (???) //referred to as a "global vertex buffer" I also included MAINPK, as she's one of the unlockable skins, just incase there's potential variation as the aformentioned character is the base skin, which allows cutscenes and hitgrunts. In addition, i've also included what appears to be the games general containers (divided by language given the final character) which includes .mesh files, which I'm assuming is static mesh. Let me know if anyone is willing to make .bms and/or noesis import/export scripts (anything that would allow me to make character replacer mods) I'd be super grateful! Psi-Ops W32s.zip -
Hello! Me and a friend, were messing with this old game files, but as expected, the files are very hard or impossible to edit "Packfile.dat". BUT, something did hit my attention was, the fact the PS2/Xbox/Wii versions has the 2Player (Split-screen) multiplayer featured, enabled and the PC Port, not. This version I'm using, are the original, with the patch 1.01 installed on. But, I mean the PC version, has a "Hidden" Multiplayer, that could be supposedely, actived... We've also discovered that the game has Debug material/stuff at your code, but for some reason, it cannot be actived, because the suppose references, was cutted from the final version, IG. However, after decompile using the ghidra and try different values with Cheat Engine, was possible we got some very interesting results, as you'll see right now! Check the images! It still doesn't over! We're still trying do reverse engineering from encrypted binary file: "Packfile.dat" which I was able to extract, some textures, using a not very, known tool: "Multi-Extractor 3.3.0" the remaing of the files are ".hnk" and ".dds" but they're technically encrypted as well. Being impossible extract or view them in any other tool! Someone do are able to develop a quickbms plugin for files of this game? if yes, let me know! I'll be glad in mod this game! :)
-
![More information about "The Last of Us Part 2 Remastered [PC]"](https://reshax.com/uploads/monthly_2025_04/ywNG2L5.thumb.jpeg.076ddc71022b5c05cac6de015e780fc7.jpeg)
Version 1.0.0
508 downloads
My old tool for TLOU2 PS4 fixed to work with PC files. Unpack .psarc files with UnPSARC_v2.7, and then you can use any .PAK file with the tool. Use command line, or just drop .PAK file onto the .exe Work same as old tool, described here: https://web.archive.org/web/20230819184855/https://forum.xentax.com/viewtopic.php?t=22580 After extraction, model and skeleton are in separate files. So they must be manually combined to work together. SMD model & skeleton can be just imported separately and then connected in blender. For ascii it will not work, so you have to open model in text editor, remove first line (0), which is bone number, and copy-paste skeleton there instead of that zero. So far tested on models, textures, maps - all looks fine. Animations are probably wrong, i can look into that later.- 1 review
-
- 13
-

-

-
- last of us
- pc
- (and 1 more)
-
Hello everyone, I have been struggling for some time to extract the assets from the .vfs file in the Steam folder of the game La Pucelle Ragnarok. I am trying to get the sprites of the game since some aren't on spriters-resource.com I tried using Ninjaripper, Renderdoc, Special K and Dragon Unpacker. The later gave results, but I only managed to get sound files. For the pictures, no matter the software, I only get some glitched, negative gray scaled or red scaled ones. My best bet is Quick BMS but I need the good encryption key... I tried this list of keys but the La Pucelle and NIS keys don't work with the Steam version of the game (NIS being the developer). I also tried with the PSP emulation ROM without success. After asking around, I got redirected to this website, would someone be able to help ? Mega link to download the relevant file Thanks for your interest ! 🙏
-
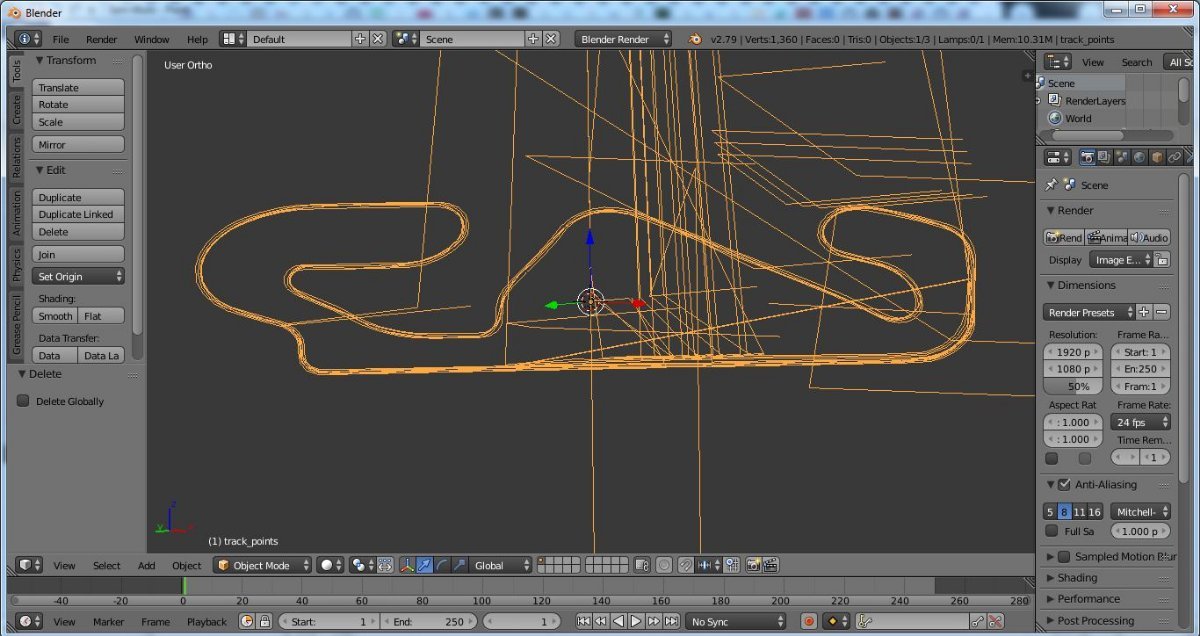
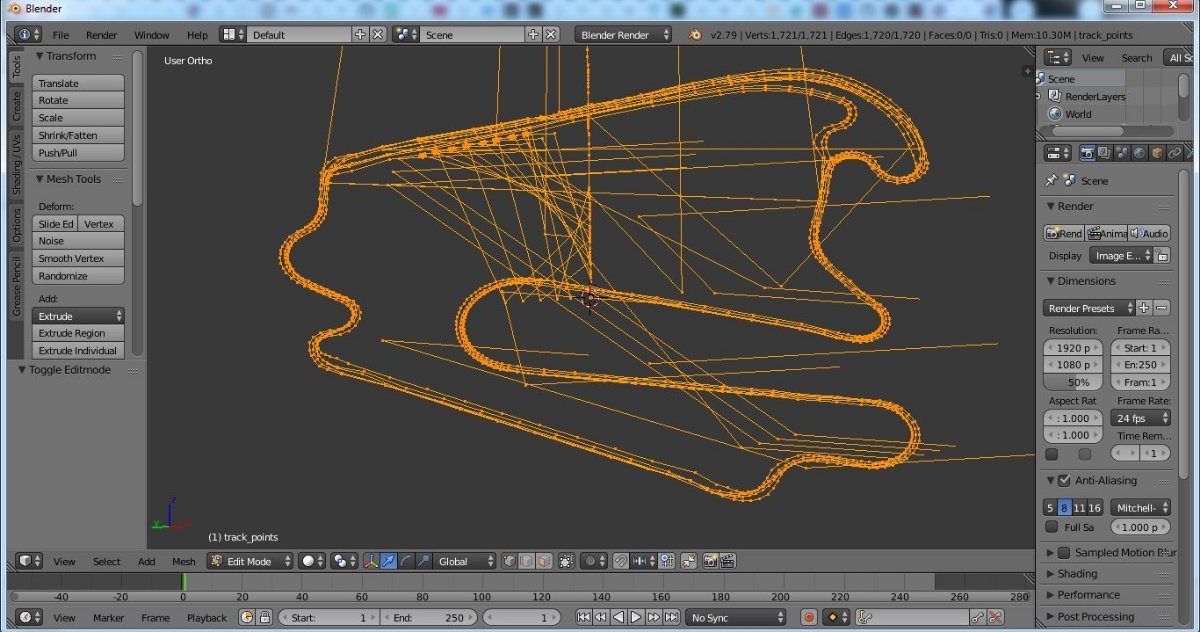
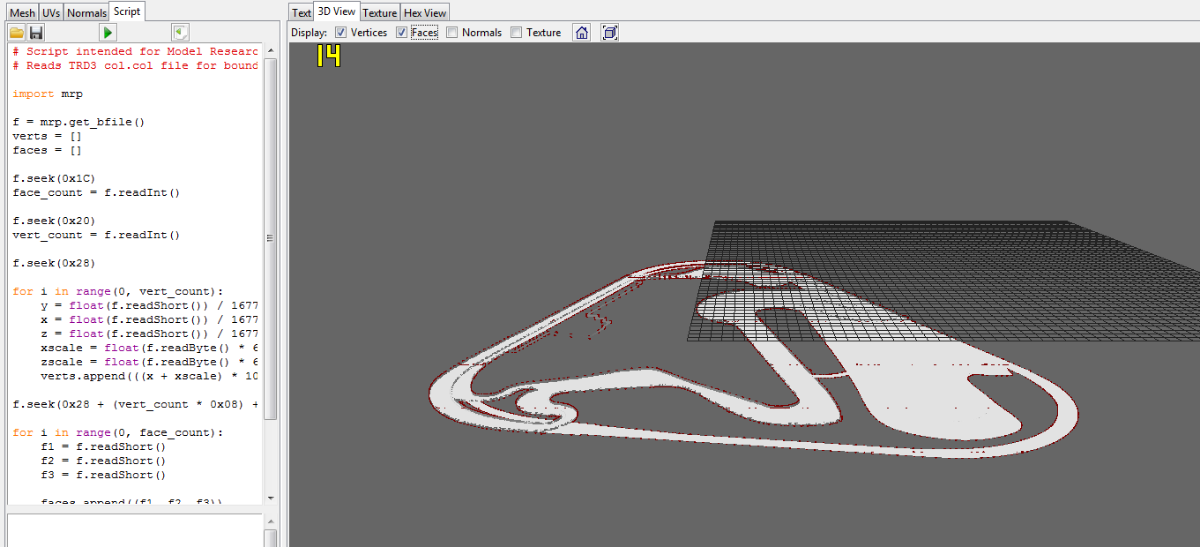
Hello! some weeks ago, i've diggin' for info about these 6 files formats, that belongs to ToCA Race Driver 3 from Codemasters, and they are: .AIL, .AIB, .RED, .AID, .COL & .PX The "AIL file" contains data about; Minimap, Track AI path, Start & Finish. The "AIB file" contains not much, but some data about the AI drivers behavior, as well. and the "RED file", despite of this funny name, seems contain some data related to Replay Paths (Like as Circuit Path) and cameras activation for some determinated area of Race track. About the AID, is same as AIL, but it is hard-codeded. and with help of chatGPT i could manage to view your geometry, that you'll see above: 1. Catalunya Circuit (from ToCA Race Driver 2), 2.Eurospeedway Lausitz Long (Also from same game) 3. COL File collision file (from Eurospeedway Circuit) 4. PX File, (Track Cone) Ok! but nothing could be done so far. Since I have no much knowledge for create any proper tool to edit this files, but would very interessing, port Circuit from RD1 & RD2 to the ToCA 3! If someone were able to do atleast proper conversors, of some these files, I would be glad! My Github repository is here: https://github.com/LFGamer2004/ToCA-Race-Driver-3-Modding-Track-Conversion-Tools LZS_EDITING_TOCA3.zip RD3format.zip
-
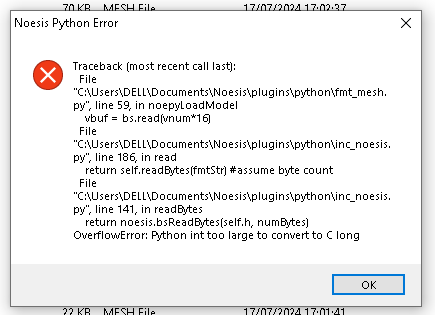
Hello, I came here asking for help regarding the PC Steam game Sky: Children of the Light. I've been trying to get the model files to open inside of Noesis, but every file appears to be a .mesh file. Natively, this format couldn't be opened in Noesis, so, about a year ago, I've commissioned a kind person to make a plug-in that supports .mesh files ("fmt_mesh.py" in attachments). Issue is, the script throws an error every time I try to preview a model (sample files as examples). The creator no longer wants to work on the script, and I have gotten permission to share and edit it. If anyone has any knowledge of this, please give it a shot, I hope the plug-in is a good foundation for the models. fmt_mesh.py samples.zip
-
A couple of sample PCAPK files found in PCPACK container. PCAPK contains textures, models, animations, etc... Hopefully anybody can help reverse the structure of the model format inside please. Sample PCAPK Files.zip
-
The .mot file possibly contains a pack of animation files. Sample .mot file (give thanks to Ryn for this file) : .mot sample file .zip
-
.minfo - Seems to contain names of the meshes used in .mmesh files. .mmesh - Model (and textures?) .sop - ??? .skeleton - Contains the bones for the model. Sample files here (give thanks to Ryn for the files) : pl0001 files.zip
-
Hi there! I’m totally bummed to hear that ZenHAX and XenTAX are going away for good. Those forums were so great and I’m going to miss them very, very much. However, it’s a new beginning that I hope to take advantage of as new file hunters come here seeking information on files to extract and share with the world. Today’s topic I’d like to bring up are the sounds from two of LucasArts’ greatest games: Star Wars: The Force Unleashed and its sequel. The reason I’m bringing this up is that the game has a whole slew of sound effects locked away in its files, particularly the sounds of the Force and the lightsabers. Now there have been uploads of these sounds elsewhere such as Sounds Resource for the PC. However, those sounds are at 22500 hz and the sounds from the second game have not labelled with proper identification as the first game. My objective is to locate sounds from both games that are not only around 44000 hz or so, but are also properly labelled with identification, so as to avoid having to hunt for the proper sounds upon being ripped and shared. If anyone has access to these files from the Xbox 360 version of both games along with its sequel, please share what you have and I will see what can be done with them.